浏览量:10951次
人工智能在金融领域的应用

一般人对于人工智能的认知都是从新闻开始的,我也从新闻说起。
1997年,IBM深蓝机器人战胜国际象棋冠军。从这个事件开始,人工智能才慢慢进入大众视野,以前只是科幻小说或科幻电影的事情。1997年的事情基本上是教科书才会提起的,但是在此后长达十几年的时期内,人工智能领域并没有发生其他爆炸式新闻。
然后,就是最近五年的事情了。
2011年,IBM深蓝机器人在综艺节目《危险边缘》中,类似国内《开心辞典》,击败两位人类冠军。人工智能的产物在电视广播中打败人类,可以说是一起轰动事件。以这次PR为基础,IBM开始了智慧城市、智慧医疗等等商业宣传。
之后到2012年,谷歌开始发力了。他们号称已经建立了5亿个实体、35亿条关系的知识谱图,可直接在搜索引擎上提供服务。
2015年,Google宣布无人车计划。
还有一个可能大家都知道的信息:2016年,AlphaGo打败了李世石。这个事件在中、日、韩等国家影响力更大,因为围棋在这些国家比较普及。
当然,这些仅仅是新闻。外行看热闹,内行看门道。我们来看看在这些新闻背后,人工智能是怎样发展的。
金融领域可能应用的人工智能技术

深度学习刚才讲了一下。它的特点是失控,黑盒子思想。仅仅设计机制,不去控制。具体就是可以自动学习特征,因果关系。只要有足够的历史数据,它即可从中学习规律,用来预测。这是一种以结果为导向的方法。深度学习一直很火,一发不可收拾,几乎统治了学术上的所有领域,到现在深度学习的热度也没有过去。然而,以前一个概念或者算法火三四年就不错了,很快就会被其他的替代。
还有就是知识图谱。知识图谱的信息是人可读、可控的。它是一种存储知识的结构,可以认为是传统数据库的升级版。升级的点在于传统数据库的最终用户是人,但知识图谱的最终用户可以是人,也可以是机器,也就是说是机器可读的数据库,它包括“回答是什么的信息”和“回答为什么的信息”。比如,机器有了知识图谱后可以问一家公司的十大股东都有谁?这个地方政府发布的政策会影响哪些房地产公司?等等。
自然语言处理也是比较好理解的。自然语言就是我们平时所说、所写的语言和文字。为什么非要加一个“自然”呢?这是相对于产生式、人为定义的语言来说的,比如编程就不是自然语言。简单地说,自然语言处理做的事情是如何让机器“浅层次理解一句话是什么意思”,可以用来处理大量非结构化数据,也可以通过公开的维基百科或研报等建立知识图谱。
信息不对称与人工智能

接下来我们再来看一下信息:
自然界中的信息有许多种,有很多信息是不可被感知的,这一部分我们不去讨论。在人可感知的信息中,一部分是语言无法表达的信息,另一部分是语言可以表达的信息。在语言可表达的信息中,一部分是公开信息,这部分信息是可采集的,也正是机器可处理的信息。在这部分信息中,一部分是非结构化信息,另一部分是结构化信息。在结构化信息中,有一部分信息构成了知识图谱,这个范畴是人工智能能做的。我们知道了人工智能可以做什么,接下来的讨论才有意义。
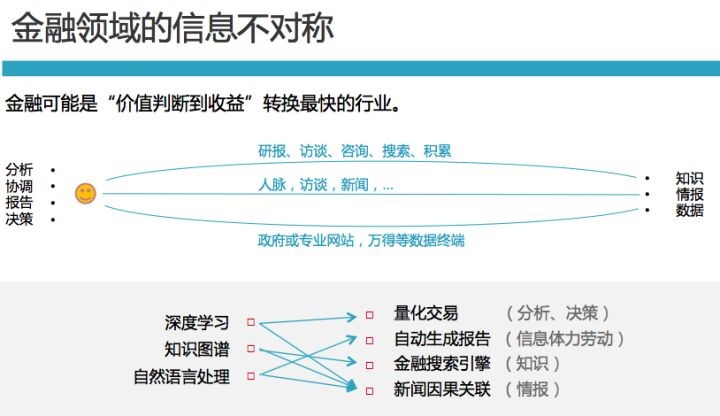
接下来我们看一下金融领域的信息。金融领域中存在三种主要的信息不对称,分别是知识不对称、情报不对称和数据不对称。所谓知识的来源,主要是研报、访谈、咨询、探索、积累等;情报的来源,主要是人脉、访谈、新闻等等;数据,则主要来自于政府或专业网站,以及一些数据终端。这三者对市场会产生不同程度的关联,其中弱关联关系才是比较有价值的信息。这里的“信息体力劳动”其实是自己创造的词,主要是指一些不需要人的洞察即可完成的工作,比如复制黏贴。其实复制黏贴占据了金融从业者很大一部分的时间,这部分工作是机器能够帮上忙的。
机器学习技术在金融领域被应用在量化投资上。

全球最大的对冲基金桥水(BridgewaterAssociates)早在2013年就开启一个新的人工智能团队。该团队约有六名员工,由曾经供职IBM并开发了认知计算系统Watson的DavidFerrucci领导。通过历史数据和统计概率预测未来。该程序将随着市场变化而变化,不断适应新的信息,而不是遵循静态指令。
RebellionResearch是一家运用机器学习进行全球权益投资的量化资产管理公司。RebellionResearch在2007年推出了第一个纯人工智能(AI)投资基金。该公司的交易系统是基于贝叶斯机器学习,结合预测算法,响应新的信息和历史经验从而不断演化,利用人工智能预测股票的波动及其相互关系,创建一个平衡的投资组合风险和预期回报,利用机器的严谨超越人类情感的陷阱,有效地通过自学习完成全球44个国家在股票、债券、大宗商品和外汇上的交易。
伦敦的对冲基金机构Castilium由金融领域大佬与计算机科学家一同创建,包括前德意志银行衍生品专家、花旗集团前董事长兼首席执行官和麻省理工的教授。他们采访了大量交易员和基金经理,复制分析师、交易员和风险经理们的推理和决策过程,并将它们纳入算法中。
量化交易方面的人工智能初创公司有日本的Alpaca。它旗下的交易平台Capitalico利用基于图像识别的深度学习技术,允许用户很容易地从存档里找到外汇交易图表并帮忙做好分析,这样一来,普通人就能知道明星交易员是如何进行交易的,从他们的经验中学习并作出更准确的交易。
坐落在香港的Aidyia致力于用人工智能分析美股市场,依赖于多种AI的混合,包括遗传算法,概率逻辑。系统会分析大盘行情以及宏观经济数据,之后会做出自己的市场预测,并对最好的行动进行表决。

不仅是机器学习,自然语言处理技术也被广泛应用在金融领域。自然语言处理技术的核心是:机器可以简单地理解一句话的大体意思。现在跟着大数据一起满大街都是的舆情应用就是自然语言处理技术的一种应用,他可以简单理解一句话中的主体(公司),还有那句话的情感。
自然语言处理技术如果仅用于舆情,那就是用牛刀杀鸡了。
我们这里看两家公司,一家是Dataminr,一家是Palantir。第二家大家可能很熟悉了,我们先看Dataminr,它是一家基于Twitter及其他公开信息的实时风险情报分析公司。社交媒体中的信息比新闻快很多。如果别人用新闻来做决策,大家都盯着新闻看的时候,会晚一步。一些突发事件也不存在小道消息或内幕消息,完全无法预测,只有发生之后最快知道的人能更快的躲避风险。算法综合考虑了Twitter用户的位置、信誉、新闻外部引用、市场容量、市场价格等因素来提供告警信息。Dataminr产品的功能包括仪表盘、截图、告警细节等,其算法综合考虑了Twitter用户的位置、信誉、新闻外部引用、市场容量、市场价格等因素来提供告警信息。此外,Dataminr的算法也考虑了告警信息的误报。其算法利用了Twitter的自修正能力—一旦某人发出的微博是有误的,马上就会有人指正,这种行为会通知Dataminr的算法引起其注意。Dataminr目前已经吸引了银行、政府、对冲基金等方面的客户,他们用这套系统来作为自己的早期预警系统。而美国证交会(SEC)现在已批准公司可以将社交网络作为新闻发布渠道,因此Dataminr的系统采用率只会越来越高。该公司正打算将产品推向更多的垂直领域。

这是我们公司(文因互联)做的一个东西,它是金融领域知识图谱生成的一次尝试。生成的知识图谱是产业链,供应链,相似企业,对标企业等,在此基础上它能给出精准的产业链提示。比如在一个行业里,前五大供应商是谁,我们也可以找到,它现在已经升级了,被整合到了我们的投研系统FinGo里。

自动生成报告也是我们跟客户的交流过程中频繁遇到的顶级需求。比如,研报中的一些模块,写各种公告,公开转让说明书,上会报告等等。我们的客户觉得其中有大量重复劳动可以用机器替代,希望我们提供一种简单操作就可以生成文本内容的工具。这里我想讲的是:自动报告技术现在达到了什么程度,能做哪些报告。
自动生成报告并不是新技术。自动生成的报告我们可以分为两类:一种是图表,一种是文本。关于图标,用过Excel表格的基本都会,不是新鲜事物。但是生成文字就不是了,不像绘制图表一样简单了。但是,生成文字也有简单的方法。按照难易度可以分为篇章级别、段落级别、句子级别。在篇章级别上用一种模板,替换里面的数字或关键字是最简单的。这个大家都能想得到,这也用不到深度学习这种技术。不过,如果使用也是可以的。段落级别的自动生成报告就有点难了,尽管还是在段落级别的模板上替换数字或关键字,但是要考虑段落的组合。句子级别那就相当难了,句子组合成一个段落真是相当不容易的。
但是,深度学习不只是替换关键字,最基本的句子也是可以自动生成的。我们不少人用过谷歌翻译,明显感觉到以前很多句子是不通顺的,就是因为哪些句子也是自动生成的。多说一句,如果是机器翻译的老用户,你们会发现最近几年机器翻译有一个质的飞跃。虽然还是那么烂,但是感觉能看得懂了。机器翻译因为有很多的平行语料,所以可以用深度学习训练。
金融领域里,我们自动生成报告遇到的难点是可以用于训练的数据不多。但是模板级别是不需要的。以应用场景为驱动,在不断迭代过程中让成本更低这个目标下,还是有信息的。
跟我们一样做这方面努力的公司在上图,可以看一下。

举一个我们自己正在做的自动生成报告的例子。我们从年报、半年报、公司主页、工商信息等等信息中提取信息,经过文本数据结构化和自然语言生成两个环节,生成PPT格式的挂牌公司报告。生成这样的报告,我们用0.4秒就能生成一份,我们用了一个小时就生成了全市场9000份新三板挂牌公司报告。这份PPT不是简单的转化,现在我们和银行合作,他们有许多需求,比如信贷尽调报告他们希望能够自动生成,这样可以防止客户经理的一些操作。

数据终端解决了基础金融数据问题。它偏向结构化数据,但是缺少碎片化文本信息的检索工具。这里就产生了搜索引擎的需求。
金融搜索引擎,是我这次分享的最后一个应用场景。通过智能的搜索和浅层语义理解技术解决信息聚类和领域垂直搜索问题。
前面已经分析了一些应用场景,但在实际与客户交流的过程中,我们遇到了无数困难,说“颠覆”两个字并不容易。我们发现目前实际应用场景中最核心的需求还是获取更多可靠的数据,而不是机器提供决策。以我们最近接触的银行客户为例子,他们的需求第一是整合银行内部数据,第二是整合外部数据。银行内部数据是原来就有的,主要是权限问题和内部管理制度问题。
而外部数据是全新的,他们会从各种渠道买来数据,比如各种黑名单、电信等等。这些数据就需要有一种好的方法统一结构存储,方便以后检索。我们所做的解决方案是金融领域个性化搜索引擎。由于是异构数据,我们需要用一定的NLP和知识图谱技术来降低构建信息查询系统的成本。还有,如果做关联搜索,必须使用知识图谱技术。比如,想知道一家投资机构背后注册的公司投资了哪些,我们爬取基金业协会、工商数据后还要进行关联。
国外,我们发现了一家类似的公司——Alphasense,主要是针对文本数据提供检索的公司。他们也通过搜索把各种相关的碎片文本信息整合到一起,方便数据浏览。
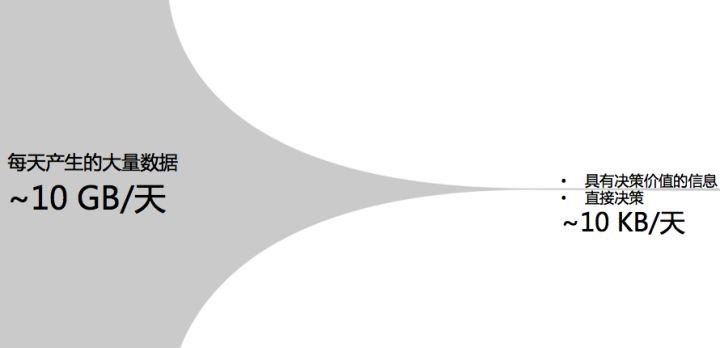
最后说一下我的设想,我们希望完成这样一个10GB/天到10KB/天的转换,从每天产生的大量数据中提取出具有决策价值的信息,帮助进行直接决策。
(来源:知乎)


0830-96830

泸州市江阳区酒城大道三段18号1号楼
 官方微信
官方微信 手机银行
手机银行 小泸云厅
小泸云厅 直销银行
直销银行本网站支持IPv6访问 版权所有©泸州银行
 川公网备案51050202000031号
蜀ICP备14004656号
川公网备案51050202000031号
蜀ICP备14004656号 
